ARIA: Building an Azure-Native Agentic AI Platform
A production-grade agentic AI platform for private-document research, built on Azure Functions, Microsoft Agent Framework, and PostgreSQL with pgvector. Achieved 100% retrieval hit-rate, full citation traceability, and zero public endpoints — deployed as a master's thesis project.
Industry
Technologies
Languages, frameworks, and platforms used in this project.
Azure Services
Concrete Azure resources and services provisioned.
Tags
Key Challenges
- •Orchestrating 7 specialized AI agents across 3 distinct workflow paths while maintaining deterministic routing and reliable handoffs between agents.
- •Implementing production-grade security with zero public data-plane endpoints, managed identity throughout, and a comprehensive 11-stage middleware pipeline.
- •Achieving high retrieval accuracy and full citation traceability over private documents using pgvector with confidence-thresholded filtering.
- •Keeping infrastructure costs explainable on an academic budget while comparing open, VNet-protected, and fully private deployment postures.
Key Outcomes
Summary
ARIA (Academic Research Intelligence Assistant) is a production-grade, Azure-native agentic AI platform designed for private-document research workflows. Built as a master's thesis at Metropolia University of Applied Sciences (March 2026), the platform combines retrieval-augmented generation with multi-agent orchestration to deliver grounded, citation-traceable research answers from private document corpora — all while maintaining enterprise-grade security with zero public endpoints.
The system integrates seven specialized agents, three distinct workflow paths (question answering, report generation with human-in-the-loop approval, and document ingestion), and an eleven-stage middleware pipeline handling authentication, PII filtering, content safety guardrails, and cost tracking. Deployed on Azure Functions Flex Consumption with managed identity and VNet isolation, ARIA demonstrates that agentic AI platforms can be built with production-oriented security at a manageable but non-trivial baseline cost when private networking is enforced.
Project Highlights
- 7 specialized AI agents orchestrated via the Microsoft Agent Framework
- 100% retrieval hit-rate and 100% citation coverage in production evaluation
- Zero public data-plane endpoints — full managed identity and VNet isolation
- Production run rate ~EUR 200/month during the active fully private evaluation window
- Solo project — designed, implemented, deployed, and evaluated as a master's thesis
The Challenge
Research Context
Large language models have expanded the scope of automated knowledge work, yet deploying retrieval-augmented generation systems with production-grade security and operational controls remains an open engineering challenge. Researchers working with private or sensitive documents cannot rely on public AI services, and existing RAG implementations typically lack multi-agent orchestration, citation traceability, and security hardening — the features that separate a prototype from a deployable platform.
This project set out to answer whether these concerns — retrieval quality, workflow orchestration, and enterprise security — could coexist in a single, deployable platform, and whether the resulting trade-offs could be made visible and measurable rather than assumed away.
Technical Challenges
- Orchestrating multiple specialized agents with deterministic routing across QA, report generation, and document ingestion workflows — each with different state management requirements.
- Implementing hybrid RAG with PostgreSQL pgvector for semantic search, including confidence-thresholded chunk filtering and section-metadata-aware retrieval.
- Building a comprehensive 11-stage middleware pipeline handling authentication, rate limiting, PII detection, content safety guardrails, semantic caching, and cost tracking — consistently applied across all workflow paths.
- Achieving a zero-trust security posture: no public endpoints, managed identity for all service-to-service authentication, VNet isolation with private endpoints, and fail-closed content safety enforcement.
- Keeping costs feasible on an academic budget while using production Azure services and making the cost of each security posture visible rather than assumed away.
Requirements
- Private-document processing with no data leaving the Azure tenant
- Multi-agent orchestration with human-in-the-loop approval for report generation
- Full citation traceability from every answer back to source document, section, and page
- Production-ready security posture suitable for enterprise deployment patterns
- Cost-efficient serverless architecture using consumption-based pricing
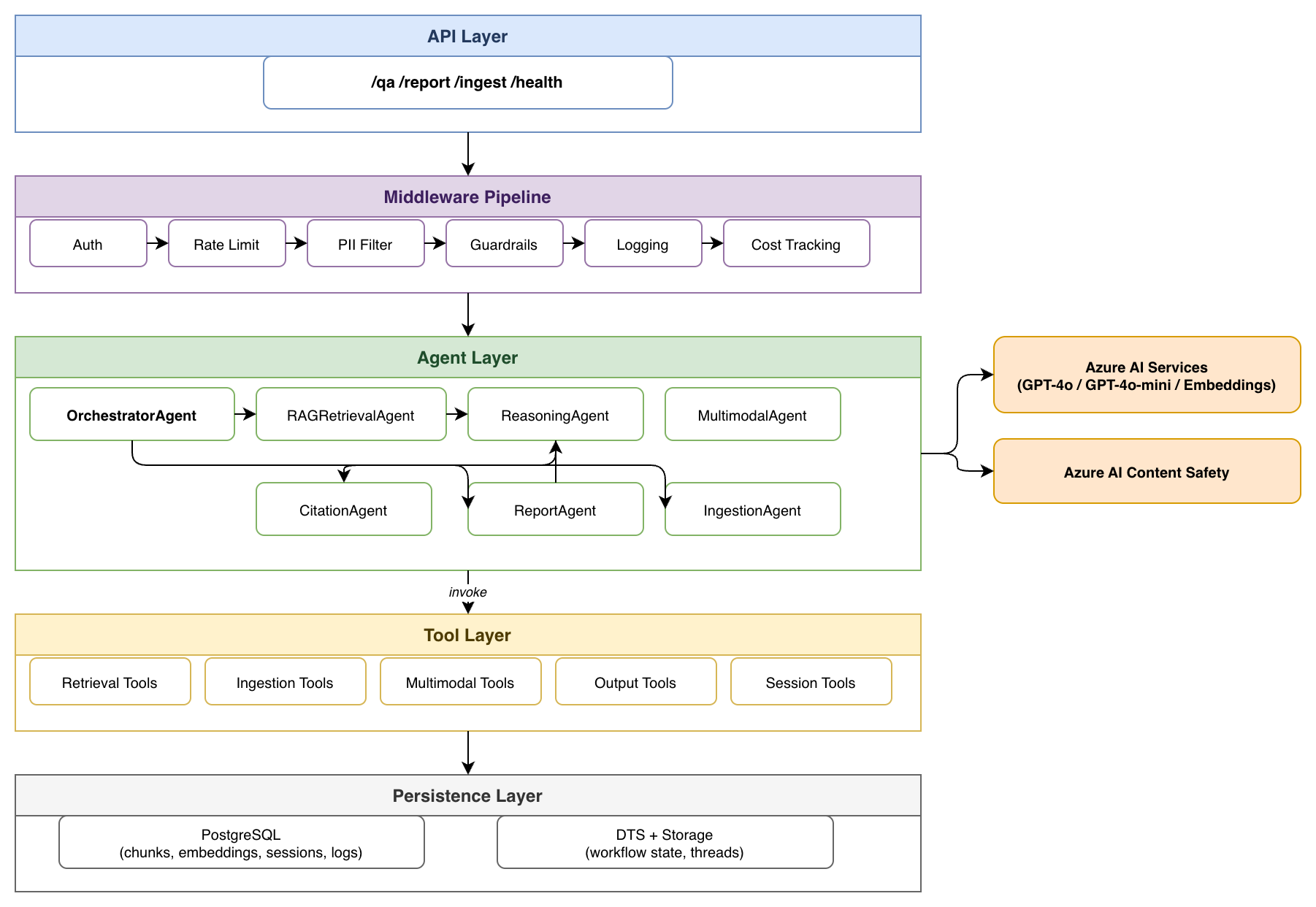
Solution Architecture
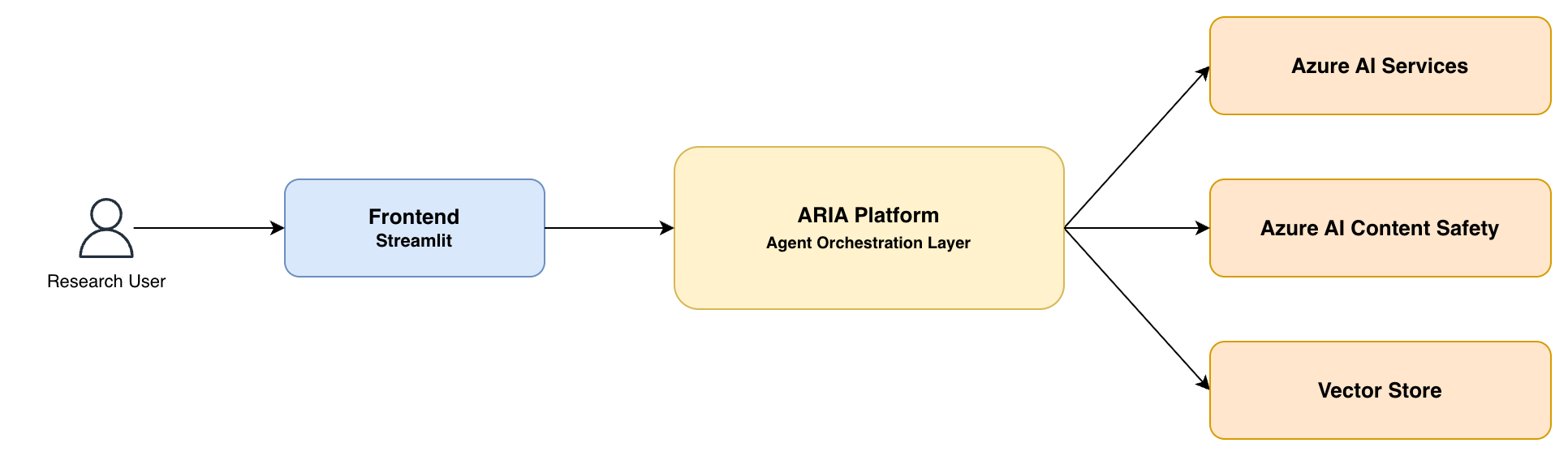
System Context
The platform sits between a Streamlit research frontend and three categories of Azure services: AI inference (Azure OpenAI), content safety (Azure AI Content Safety), and vector-backed persistence (PostgreSQL with pgvector). Every boundary crossing between the platform and an external service is subject to managed identity authentication and, in production, private endpoint networking.
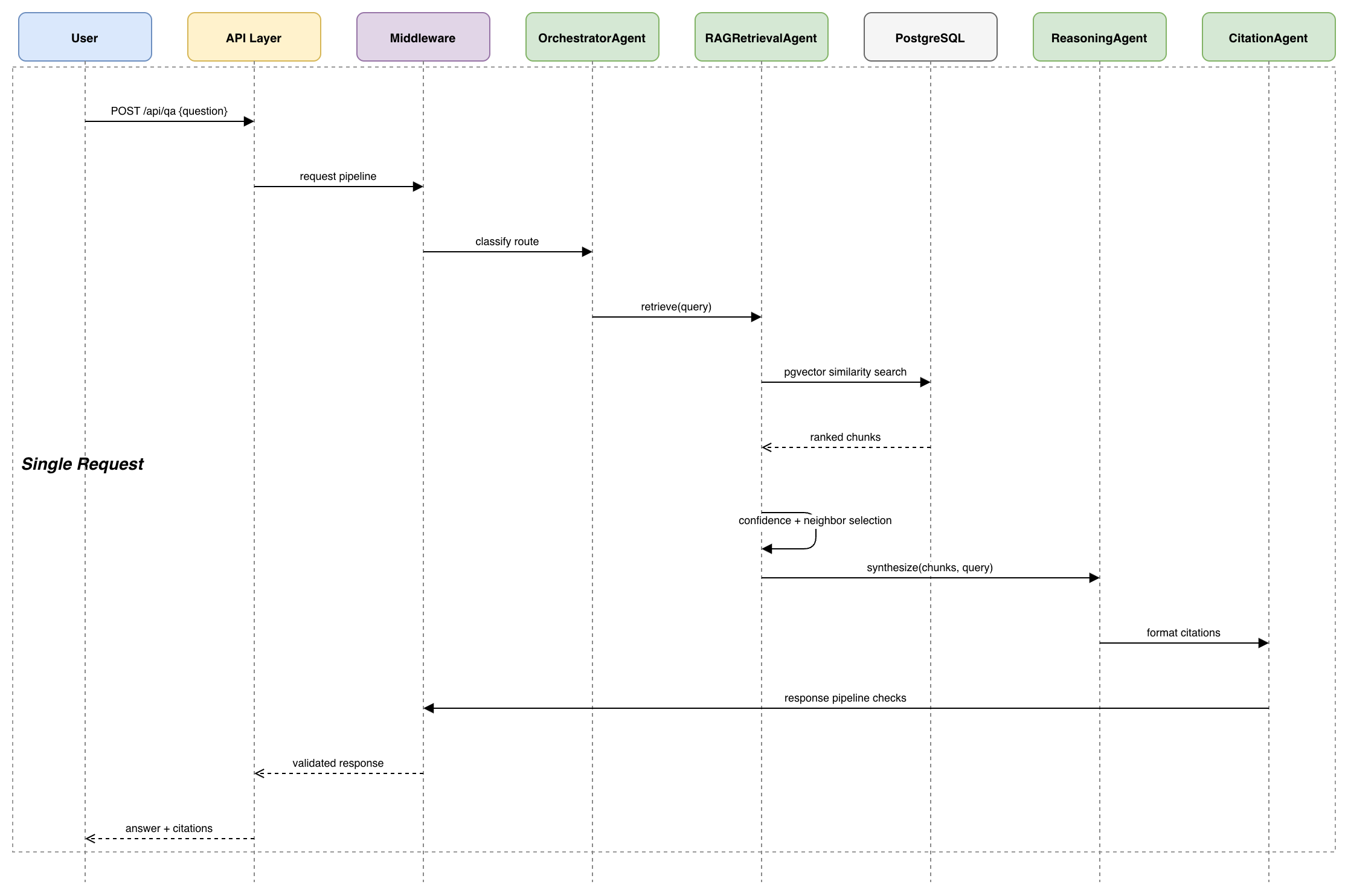
Agent Architecture
The system uses seven specialized agents, each responsible for a distinct aspect of the research workflow:
| Agent | Role | Workflows |
|---|---|---|
| OrchestratorAgent | Classifies request intent, routes to appropriate workflow, coordinates agent handoffs | All |
| RAGRetrievalAgent | Performs pgvector semantic search with confidence filtering and neighbour expansion | QA, Report |
| ReasoningAgent | Synthesizes retrieved context into coherent, multi-hop research answers | QA, Report |
| MultimodalAgent | Processes figures, tables, and visual content from documents | QA, Report |
| CitationAgent | Validates source references and formats APA 7th citations with confidence thresholds | QA, Report |
| ReportAgent | Orchestrates structured report generation with human-in-the-loop approval lifecycle | Report |
| IngestionAgent | Manages document parsing, section-aware chunking, embedding, and idempotent indexing | Ingestion |
Middleware Pipeline
11-Stage Request Pipeline
Every request passes through an 11-stage middleware pipeline before reaching agents: Authentication (managed identity validation), Rate Limiting (per-session throttling), Request Validation, PII Detection & Filtering, Input Guardrails (Azure AI Content Safety), Semantic Caching (dedup of repeated queries), Cost Estimation (pre-execution budget checks), Input Transformation, Agent Dispatch, Output Guardrails (response safety checks), and Structured Logging (per-request telemetry to query_logs).
The fixed ordering of middleware stages is a structural requirement — it ensures that security and observability controls are applied consistently before any workflow-specific logic executes, preventing individual workflow paths from bypassing safety checks. The fail-closed content safety configuration (CONTENT_SAFETY_FAIL_CLOSED=true) ensures that service unavailability defaults to blocking rather than bypassing, a critical property for platforms handling sensitive research data.
Agent Workflows
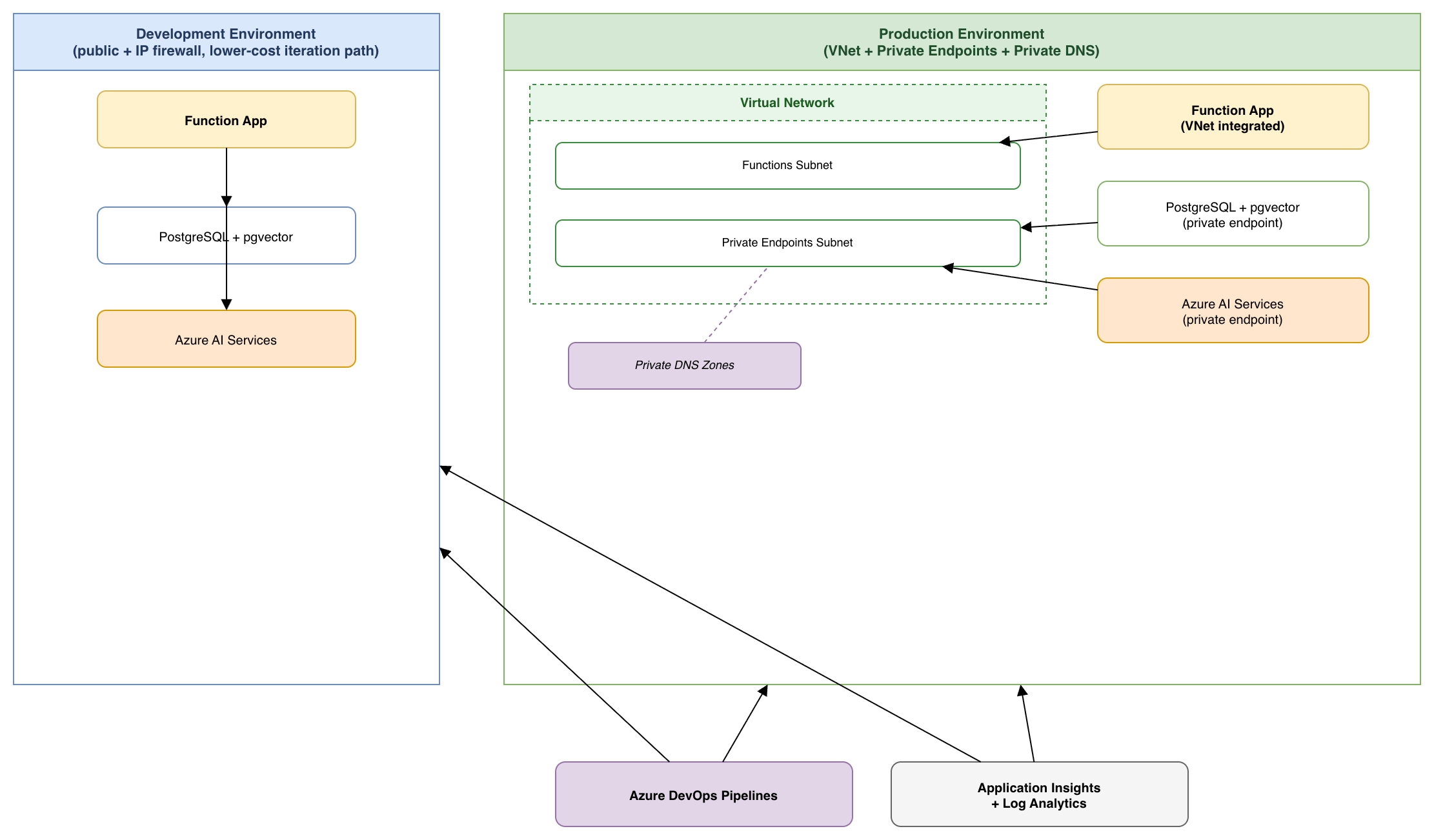
QA Workflow
The question-answering path implements a linear flow from intent classification through retrieval, synthesis, and citation-packaged response.
The OrchestratorAgent classifies each incoming request as simple_qa, chitchat, or report_intent. For QA requests, the RAGRetrievalAgent performs pgvector similarity search with a configurable minimum cosine similarity threshold (PGVECTOR_MIN_REFERENCE_SCORE), filtering out low-confidence chunks before they reach the ReasoningAgent. This confidence gating is the primary mechanism for ensuring citation defensibility — only chunks meeting the threshold are exposed to synthesis and referenced in the final response.
Report Generation with Human-in-the-Loop
The report workflow implements a stateful lifecycle with draft generation, human approval, and finalization — the most complex workflow due to its multi-step nature and persistent state management:
- Request submission — The user submits a research question via
POST /api/report - Evidence gathering — The ReportAgent orchestrates parallel evidence collection: one lane gathers text-based evidence via RAG, another gathers figure-oriented evidence via the MultimodalAgent
- Draft synthesis — Evidence lanes merge; the ReasoningAgent generates a structured draft with citations
- Approval checkpoint — The draft is persisted in PostgreSQL with
pending_approvalstatus; the system returns anapproval_idand suspends the workflow without consuming compute - Human review — The reviewer inspects the draft and issues
POST /api/report/approveto approve or reject - Finalization — On approval, the report is finalized with full event audit trail accessible via
GET /api/report/events
The workflow is durably suspended during human review using the Durable Task Scheduler — no polling, no idle compute. The system resumes exactly from its checkpoint when the reviewer responds.
Document Ingestion
The ingestion path processes documents through extraction, section-aware chunking, embedding generation (via text-embedding-3-small), and idempotent storage in PostgreSQL. Each chunk carries a labelled section path (e.g., "3.2 Related Work"), enabling the retrieval stage to return contextually situated evidence rather than decontextualised text fragments. A unique constraint on (document_id, chunk_index) prevents duplicate chunk accumulation on re-ingestion.
Infrastructure & Security
Deployment Topology
ARIA uses a dual-environment architecture that deliberately separates rapid-iteration development from production-grade security:
Security Architecture
Zero-Trust Security Posture
- Zero public data-plane endpoints in production — all services behind private endpoints within a VNet
- Managed identity everywhere — no connection strings, no stored secrets, no credential rotation
- VNet isolation with dedicated subnets for Functions and private endpoints, plus private DNS zones
- PII filtering in the middleware pipeline before any data reaches AI services
- Azure AI Content Safety with fail-closed enforcement — service unavailability blocks rather than bypasses
- RBAC alignment — managed identity roles assigned for OpenAI, Storage, Monitoring, and Content Safety
- 8/8 security readiness checkpoints validated in production deployment
All infrastructure is defined as code using Bicep templates, enabling repeatable provisioning across environments. The production deployment was validated through eight checkpoints covering VNet integration, private endpoint confirmation for all data-plane services, health endpoint responsiveness, and CI/CD verification gates.
Results & Evaluation
Retrieval & Performance Metrics
| Metric | Value | Details |
|---|---|---|
| Retrieval Hit-Rate | 100% | 10/10 test queries returned relevant documents from the 6-document corpus |
| Citation Coverage | 100% | Every generated answer included traceable APA 7th citations |
| High-Confidence Citations | 100% | vs. 52% baseline without confidence filtering |
| QA Latency (p50) | 1,559 ms | Median response time in production environment |
| QA Latency (p95) | 9,418 ms | 95th percentile — complex multi-agent queries with cold starts |
| Guardrail Accuracy | 60% | 6/10 adversarial scenarios correctly blocked |
| Route Classification | 63.6% | Intent classification across 11 test prompts |
Comparative Analysis
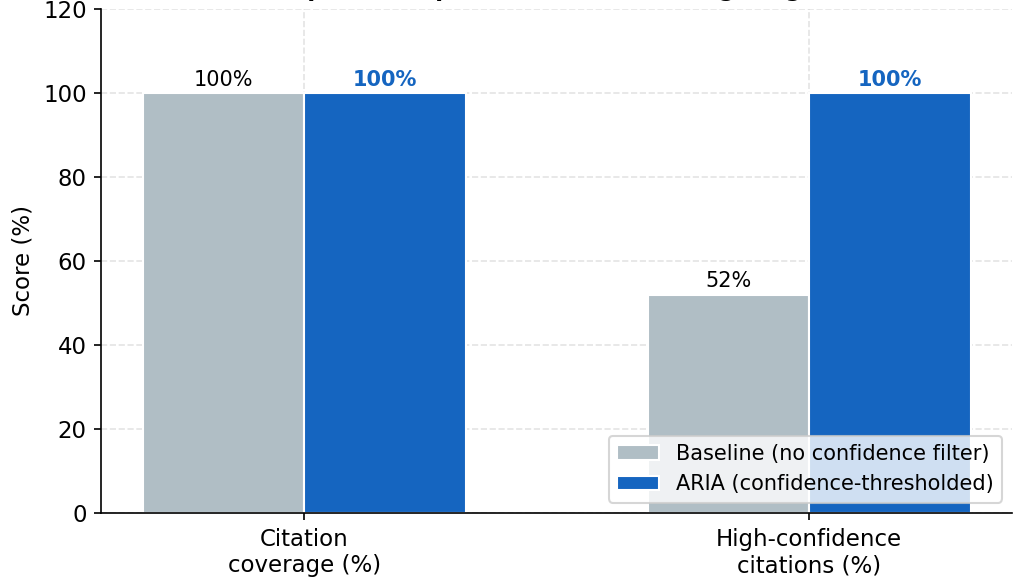
The confidence threshold parameter (PGVECTOR_MIN_REFERENCE_SCORE) has a direct, measurable effect on citation quality. Without filtering, the baseline system exposes all retrieved chunks regardless of relevance, producing noisy citations. ARIA's confidence gating ensures only high-scoring chunks reach synthesis, dramatically improving citation defensibility.
Cost Analysis
Azure Cost Management data for the historical production resource group (rg-aria-prod-sdc) shows that the original $10/month figure understated the active production baseline by roughly an order of magnitude. During the period when ARIA was active in the production subscription (2026-02-27 to 2026-03-04), measured spend was EUR 42.94 across six active days, implying an active run rate of roughly EUR 180-220/month for the fully private topology. For the case study, ~EUR 200/month is the most defensible single-number summary.
The more important finding is architectural rather than numerical: at thesis-scale traffic, network posture dominated spend more than token usage or function execution. The largest cost driver in the measured window was VPN Gateway (EUR 19.73 over the active six-day sample), followed by Durable Task Scheduler, PostgreSQL, and VNet-related charges.
Security Posture Comparison
| Environment | Public ingress | VNet integration | Private endpoints | VPN / private DNS | Cost position | Status |
|---|---|---|---|---|---|---|
| Open lower environment | Yes | No | No | No | Low single digits / month | Measured during thesis development |
| Fully private production | No | Yes | Yes | Yes | ~EUR 200 / month active run rate | Measured in production during late Feb to early Mar 2026 |
This comparison matters because the step-up in cost was not caused by the application becoming "large"; it was caused by the move from an open research environment to a private-network enterprise posture. Teams reproducing ARIA for internal pilots do not need to assume the fully private baseline immediately, but teams targeting regulated or security-sensitive deployments should expect the networking layer to dominate baseline spend. Intermediate postures, such as VNet integration without full private endpoint coverage, were considered architecturally but were not empirically measured in this project.
What Belongs to ARIA vs Supporting Platform
To avoid overstating the cost of the application itself, it is useful to separate ARIA-specific services from delivery-environment and supporting-platform overhead:
| Category | Included services | Why it matters |
|---|---|---|
| Core ARIA application cost | Azure Functions, PostgreSQL + pgvector, Foundry / model usage, Azure Monitor, Key Vault, storage | These are the services required to run the agentic application and process research workflows |
| Security posture overhead | VPN Gateway, private endpoints, private DNS, VNet-related charges | These costs buy isolation and private connectivity rather than additional application functionality |
| Supporting platform / delivery tooling | DevOps agent infrastructure, DevCenter, temporary test VMs, shared admin resources | These support engineering operations and environment management, not ARIA request processing itself |
This segregation is important for two reasons. First, it makes the thesis result reproducible: readers can see what they must provision to reproduce ARIA itself versus what was specific to the surrounding delivery environment. Second, it clarifies that the fully private production cost should be interpreted as the cost of a security posture, not as the minimum cost of the application logic.
Lessons Learned
What Worked Well
- Unified PostgreSQL + pgvector eliminated the operational complexity of managing separate vector and relational databases — conversations, embeddings, query logs, and approval records all live in one schema.
- Azure Functions Flex Consumption provided true scale-to-zero economics — no idle capacity costs during development pauses or between evaluation runs.
- Microsoft Agent Framework simplified multi-agent orchestration patterns with consistent agent lifecycle management and tool binding.
- Managed identity throughout eliminated an entire class of security vulnerabilities — no connection strings to rotate, no secrets to leak, no credential management overhead.
Honest Limitations
Areas for Improvement
- Route classification (63.6%) needs refinement — the OrchestratorAgent reliably identifies factual QA but struggles with ambiguous queries spanning chitchat and report-intent boundaries in short prompts.
- Guardrail accuracy (60%) indicates Azure AI Content Safety alone is insufficient for domain-specific adversarial inputs — custom guardrails with tuned thresholds are needed for high-stakes environments.
- p95 latency (9.4s) is high for complex queries — streaming responses and parallel agent execution would reduce perceived wait time in production use.
- Evaluation corpus (6 documents, 10 queries) demonstrates system functionality but is insufficient to characterize generalizability — expanded evaluation with human-judged quality assessment is needed.
Key Takeaways
Recommendations for Azure Agentic AI Projects
- Separate workflow routes explicitly and early — defining distinct request paths for QA, report generation, and ingestion before implementing simplifies per-route policy enforcement, telemetry, and testing.
- Treat confidence thresholding as governed configuration — the minimum similarity score governing which retrieved chunks reach synthesis is a first-class config item with observable impact on citation quality, not a tuning detail to bury in code.
- Integrate security controls from the beginning — every security control added in a later iteration required adjustments to surrounding components that had assumed simpler authentication models. Design it in from day one.
- Build scripted validation and telemetry early — the five verification gates in ARIA's deployment pipeline provided both deployment confidence and reproducible evaluation evidence. Telemetry instrumentation cannot be added as an afterthought.
- Record measurement context with every result — cloud service behavior varies with load and region. Results without recorded measurement context (when, where, what configuration) cannot be reliably reproduced.
Conclusion
ARIA demonstrates that agentic AI platforms can be designed, implemented, and deployed on Azure with production-grade security controls while remaining tractable within the constraints of a single-engineer project. The platform contributes a reusable implementation pattern — seven agents, three durable workflows, eleven middleware stages, and a zero-trust deployment topology — backed by empirical evidence on the trade-offs between retrieval quality, operational complexity, and security overhead.
The strongest contribution is not algorithmic novelty but architectural and operational viability. The cross-cutting insight from this project is that quality, operability, and security are interdependent dimensions: teams cannot improve retrieval quality without accepting orchestration complexity, cannot simplify operations without relaxing security, and cannot achieve security without investing in integration overhead. Making these trade-offs visible and measurable — rather than assuming them away — is what separates deployable platforms from prototypes.
This case study presents ARIA, developed as a master's thesis at Metropolia University of Applied Sciences. It demonstrates Cosmic Eye's expertise in Azure AI architecture, agentic AI systems, and production-grade cloud deployments. Contact us to discuss how we can help with your Azure AI initiatives.