
Established a governed, multi-workspace Azure Databricks platform with Unity Catalog, secure networking, and automated infrastructure provisioning, enabling multiple data teams to collaborate at scale.
Industry
Technologies
Languages, frameworks, and platforms used in this project.
Azure Services
Concrete Azure resources and services provisioned.
Tags
Key Challenges
- •Designing a governed multi-tenant Databricks setup supporting multiple domains and projects.
- •Implementing compute policies to optimize cost across personal, pool, and job workloads.
- •Automating provisioning of workspaces, catalogs, schemas, and access rights with Infrastructure as Code.
- •Enforcing consistent networking and security isolation across environments.
Key Outcomes
Summary
We implemented a Global Data Platform leveraging Azure Databricks, Unity Catalog, and Azure-native services. The solution established multi-workspace governance, secure networking, and automated provisioning with Terraform and Azure DevOps. Multiple engineering and data science teams now onboard seamlessly with consistent governance and cost efficiency.
Project Highlights
- Unity Catalog adoption for centralized governance
- Multi-environment setup (Dev, Test, Prod, Shared)
- Cost savings through cluster pools and policies
- Automated provisioning with Terraform and Azure DevOps
The Challenge
Business Context
The client required a shared yet governed analytics platform to serve multiple domains and projects. Each team needed flexibility, but with consistent security, governance, and cost management.
Technical Challenges
- Multi-workspace setup across Dev, Test, Prod, and Shared environments.
- Defining compute governance across personal, pool, and job clusters.
- Automating provisioning of catalogs, schemas, cluster policies, and SQL warehouses.
- Managing identity and access with domain-specific Entra groups and SCIM.
- Securing connectivity and networking for Databricks control, data, and compute planes.
Requirements
- Governed platform with Unity Catalog as the foundation.
- Infrastructure-as-Code automation for provisioning Databricks resources.
- Networking isolation for control, compute, and storage.
- Role-based access control for readers, developers, operations, and service principals.
Solution Architecture
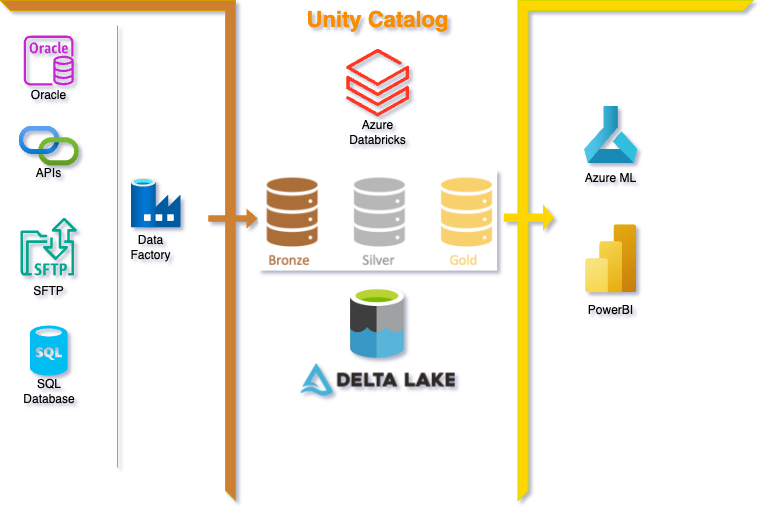
Core Infrastructure Components
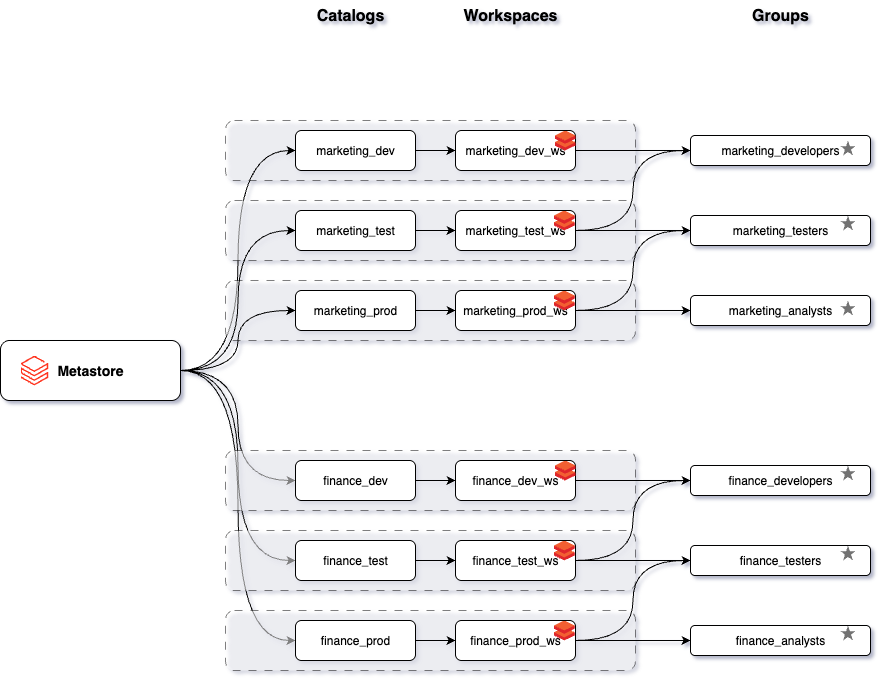
Governance Layer
- Unity Catalog as the central governance plane for all domains.
- Catalogs mapped to domains, schemas to projects, with fine-grained permissions applied through Entra groups.
- Automated provisioning of catalogs, schemas, and grants via Terraform.
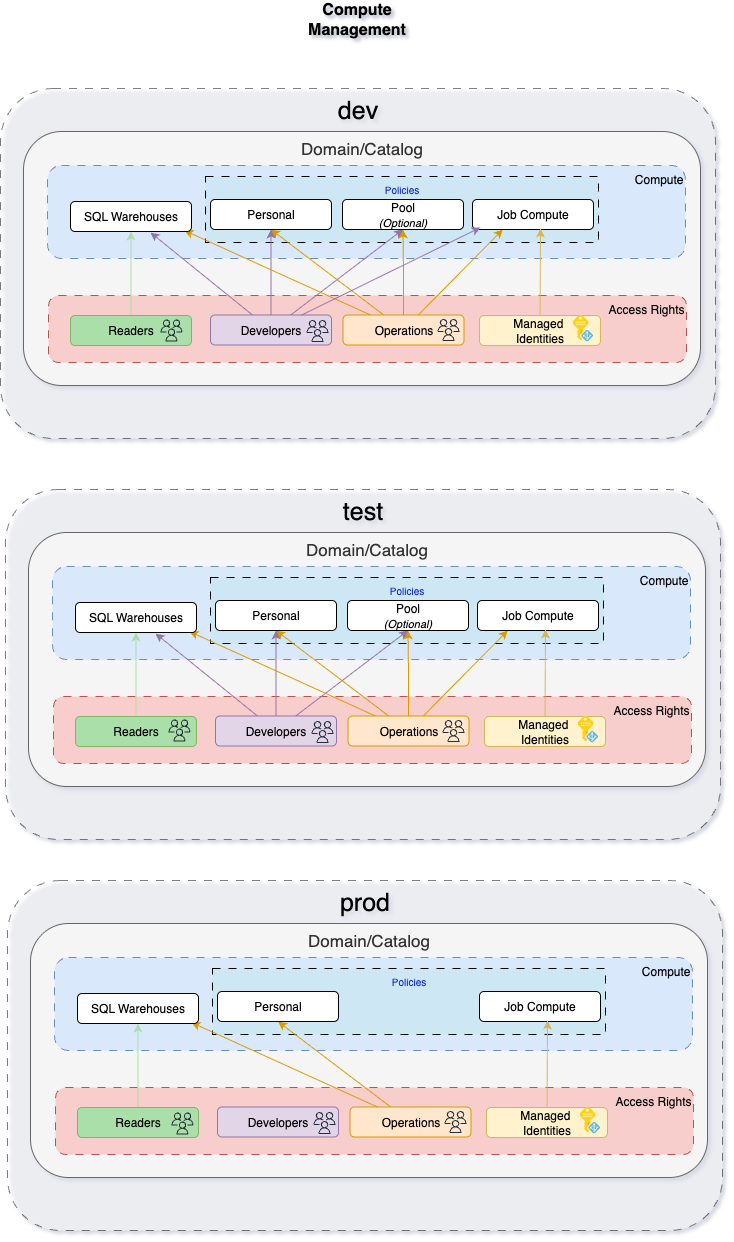
Compute Layer
- Cluster pools and policies enforced for personal, shared, and job clusters.
- SQL Warehouses provisioned for BI use cases.
- Automated entitlement of compute to roles (reader, developer, operations).
- Policies ensure environment-specific access rights (dev, test, prod).
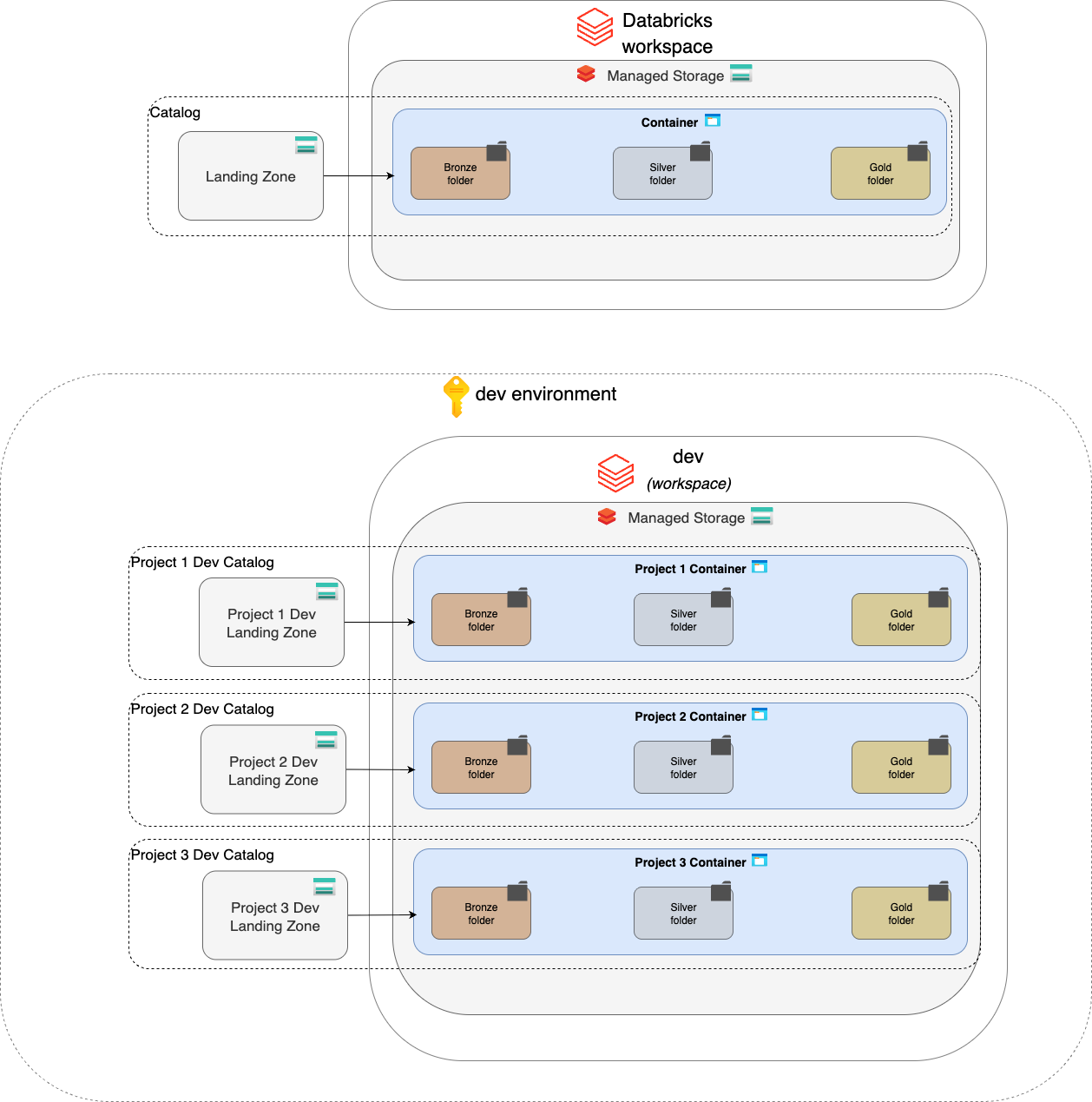
Data Layer
- Azure Data Lake Storage Gen2 containers mapped to Unity Catalog catalogs.
- Bronze, Silver, and Gold structured storage model per domain.
- Managed identities used for storage access via Databricks.
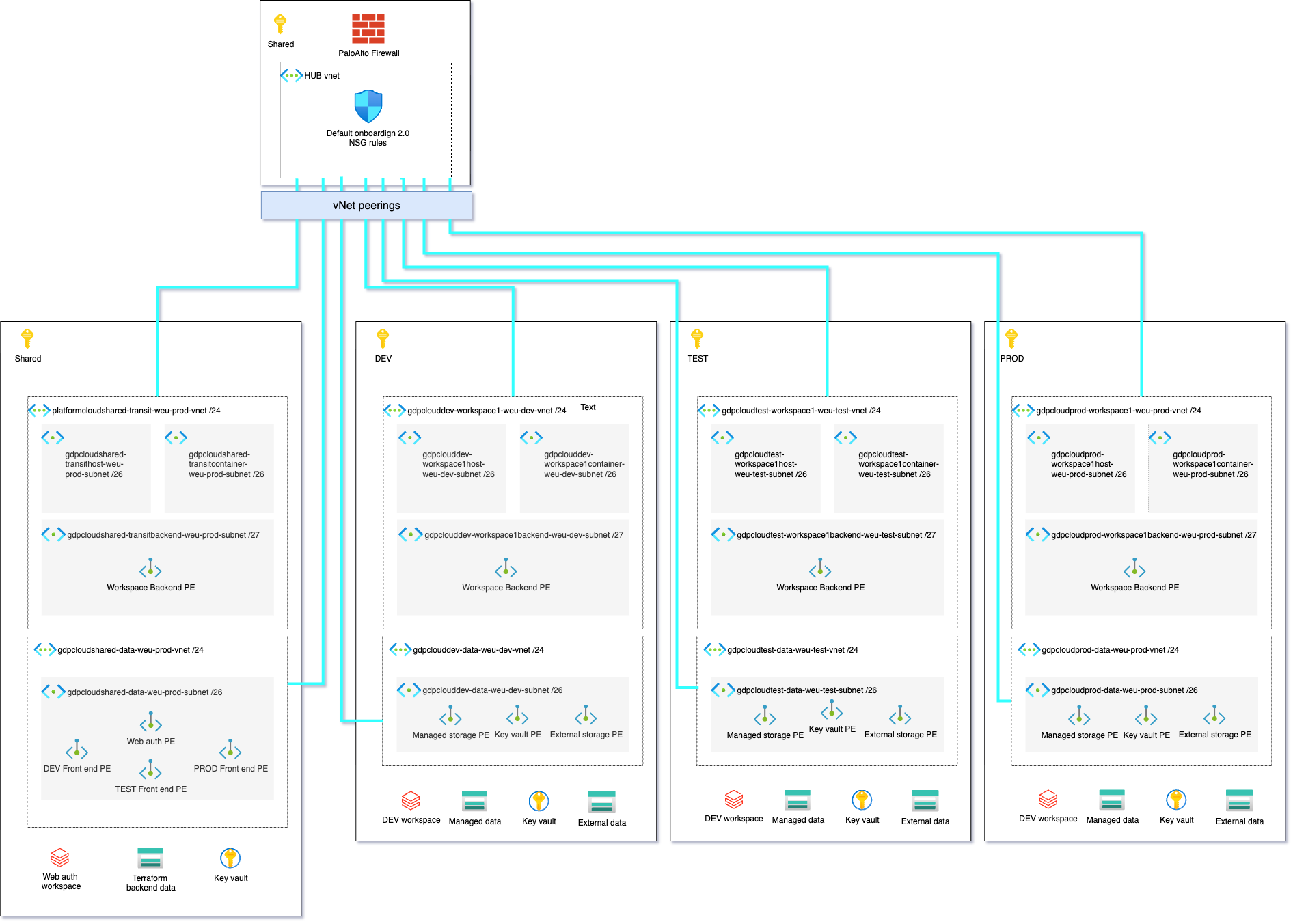
Networking Layer
Networking Principles
Control, compute, and data planes are secured following Databricks recommended best practices. Network boundaries are enforced at every layer to ensure isolation between environments.
- Hub-and-spoke vNet topology with a centralized hub and spoke vNets for shared, dev, test, and prod workspaces.
- Private Link and vNet injection for secure workspace-to-data connectivity.
- Firewall rules on storage accounts, restricting access to Databricks-managed subnets.
- Azure Key Vault integration with private endpoints for secrets and credentials.
- Centralized observability with Azure Monitor for activity logging and telemetry.
Implementation Process
Phase 1: Foundation
- Provisioned workspaces (Dev, Test, Prod, Shared).
- Integrated Entra ID for identity management.
Phase 2: Governance
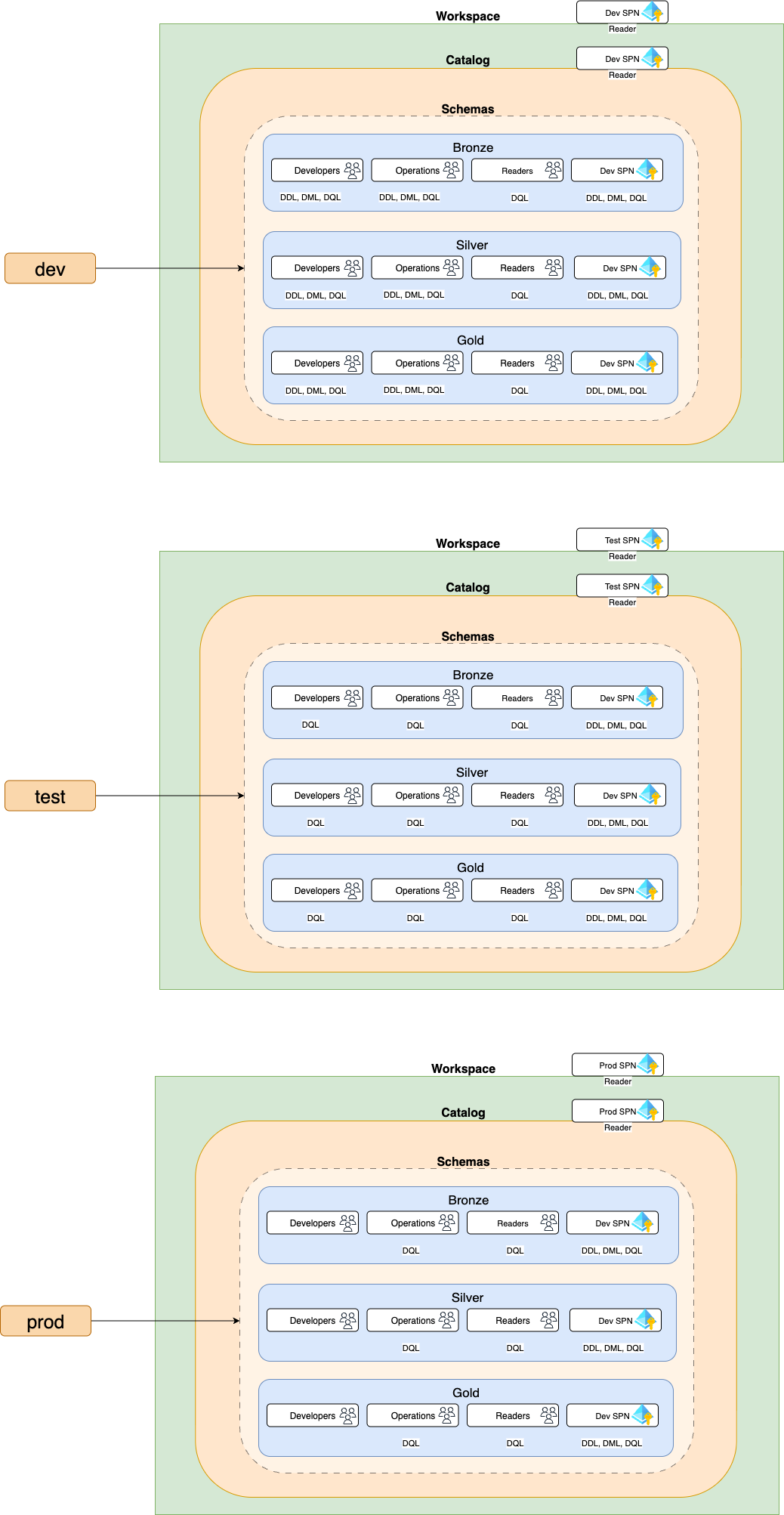
- Domain-specific Entra ID groups created to separate responsibilities (readers, developers, operations, service principals).
- Role-based access control enforced in Unity Catalog across Bronze, Silver, and Gold schemas.
- Environment-specific access models: broader permissions in dev, restricted in test, read-only for most users in prod.
- Unity Catalog provisioning automated with Terraform.
- Service principals integrated for workload access with least-privilege policies per environment.
To codify governance, we used Terraform grants. The snippet below shows how catalogs and schemas are granted to groups:
- All groups get a default
BROWSEprivilege for discovery. - Developers get higher privileges (
CREATE_TABLE,SELECT, etc.). - Readers are restricted from accessing Bronze schemas.
# Catalog grants — baseline discovery
resource "databricks_grants" "catalog" {
for_each = local.catalog_grants
catalog = each.key
dynamic "grant" {
for_each = { for g in each.value.grants : g.user_group => g }
content {
principal = grant.value.user_group
privileges = distinct(concat(grant.value.privileges, ["BROWSE"]))
}
}
}
# Schema grants — skip Bronze for Readers
resource "databricks_grants" "schema" {
for_each = local.schema_grants
schema = each.key
dynamic "grant" {
for_each = {
for g in each.value.grants :
g.user_group => g
if !(split(".", each.key)[1] == "bronze" && endswith(g.user_group, "READERS"))
}
content {
principal = grant.value.user_group
privileges = grant.value.privileges
}
}
}
Phase 3: Compute & Workflows
- Policies deployed for all-purpose and job clusters.
- Workflows onboarded using Databricks Asset Bundles (DABs).
Minimal baseline for local.default_policy (kept small for readability):
locals {
default_policy = {
"node_type_id": {
"type": "allowlist",
"values": ["Standard_DS3_v2", "Standard_D4ds_v4", "Standard_D8ds_v4"],
"defaultValue": "Standard_DS3_v2"
},
"spark_version": {
"type": "unlimited",
"defaultValue": "auto:latest-ml"
},
"cluster_type": {
"type": "fixed",
"value": "all-purpose"
},
"autotermination_minutes": {
"type": "range",
"minValue": 5,
"maxValue": 60,
"defaultValue": 15
},
"custom_tags.Team": { "type": "fixed", "value": var.team },
"custom_tags.Env": { "type": "fixed", "value": var.environment }
}
}
Job policy:
# Cluster policy for scheduled jobs
resource "databricks_cluster_policy" "job_policy" {
name = "${replace(var.user_group, " Developers", "")} Job Policy"
definition = jsonencode(merge(local.default_job_policy, var.job_policy_overrides))
}
resource "databricks_permissions" "use_job_policy" {
cluster_policy_id = databricks_cluster_policy.job_policy.id
access_control {
group_name = var.user_group
permission_level = "CAN_USE"
}
}
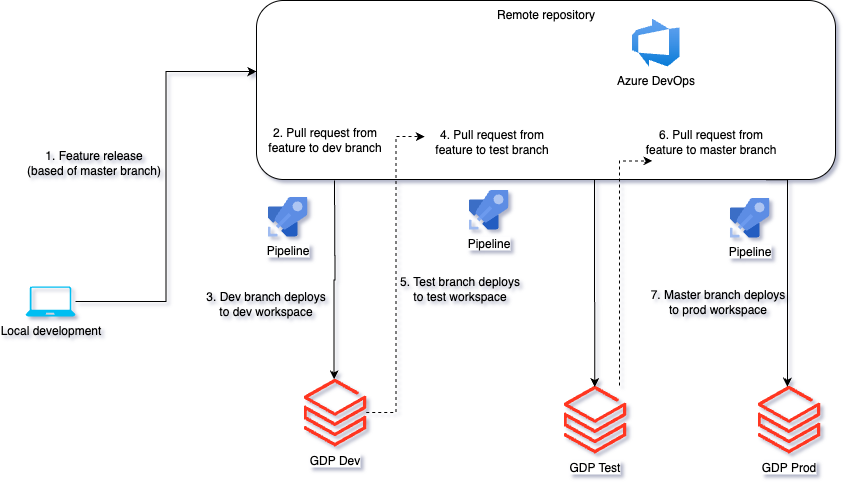
Phase 4: Automation
- Environment-specific DevOps pipelines for IaC and Databricks assets.
- Standardized branching strategy (feature → dev → test → master).
- Automated workspace deployments via Azure DevOps pipelines.
- Quality gates and pull request reviews embedded in pipelines.
- Git integration for version control, traceability, and rollback.
Results and Outcomes
Performance Improvements
- Project onboarding reduced from 3–4 weeks to 2 weeks (40% faster).
- Manual setup effort cut by 90% through automation.
- Cluster start latency reduced from
>5 minutesto<1 minutewith pools (80% faster).
Cost Savings
- 30% compute savings from pool-based clusters.
- Idle clusters eliminated with job compute policies.
Business Impact
- Standardized governance improved trust in data products.
- Teams can onboard without re-architecting infrastructure.
- Consistent DevOps pipelines ensured repeatability.
Lessons Learned
What Worked Well
- Unity Catalog accelerated governance and access management.
- Terraform reduced manual effort and improved consistency.
Challenges Overcome
- Balancing domain flexibility with centralized control.
- Networking configuration for Databricks control and data plane.
Key Takeaways & Best Practices
Key Recommendations
- Adopt Unity Catalog early to unify governance.
- Use Terraform and DevOps pipelines to standardize deployments.
- Enforce cluster pools and policies for cost control.
- Secure networking with Private Link and vNet injection.
- Manage access with Entra ID groups aligned to domains.
Conclusion
The Global Data Platform onboarding successfully delivered a governed, cost-optimized, and automated Databricks environment. With Unity Catalog, secure networking, and Terraform automation, the client established a strong foundation for future data and AI initiatives.