
Modernization of a legacy on-prem analytics platform into Azure SQL Database and Synapse pipelines. The project delivered 99.9% uptime, full automation of cube refreshes with Azure Functions, and faster reporting for business stakeholders through Power BI.
Industry
Technologies
Languages, frameworks, and platforms used in this project.
Azure Services
Concrete Azure resources and services provisioned.
Tags
Key Challenges
- •Frequent downtime and fragile on-prem SQL Server environment.
- •Migrating 2 TB of data and 150+ database objects with minimal disruption.
- •Manual, error-prone ETL processes lacking scalability.
- •Analysis Services cubes required manual refresh, delaying business reporting.
- •Security, identity, and monitoring gaps in the legacy setup.
Key Outcomes
Summary
The client’s legacy on-prem analytics platform suffered from frequent downtime, manual ETL processes, and stale reporting. Our team modernized the platform by migrating SQL Server workloads (~2 TB, 150+ objects) to Azure SQL Database, re-engineering ETL with Azure Synapse pipelines, and automating cube refreshes using Azure Functions. As a result, the business achieved 99.9% uptime, fully automated reporting pipelines, and faster insights delivered through Power BI.
Project Highlights
- 99.9% uptime achieved with Azure high-availability design
- ETL re-engineered into Synapse pipelines, reducing manual effort by 70%
- Cube refresh automation with Azure Functions
- 2x faster reporting through Power BI dashboards
The Challenge
Business Limitations
- Unreliable on-premise SQL Server environment causing report downtime.
- Reports delayed due to manual cube refreshes.
- Business decisions hindered by outdated and inconsistent data.
Technical Hurdles
- Migration of ~2 TB data and 150+ database objects.
- Replacing legacy SSIS workflows with scalable, cloud-native ETL.
- Automating downstream cube refreshes with minimal disruption.
- Enforcing modern security, RBAC, and monitoring standards.
Solution Architecture
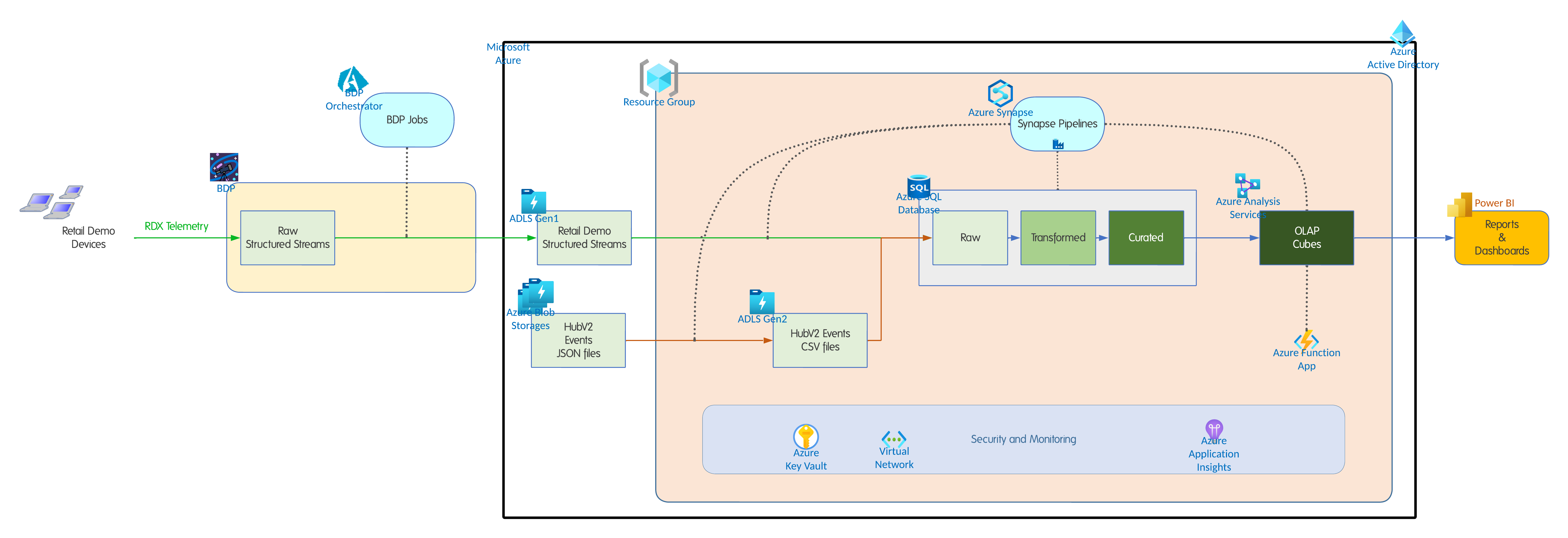
Core Components
Data Layer
- Azure SQL Database: Centralized warehouse for 2 TB+ migrated data.
- Azure Database Migration Service: Used to migrate schema and data with minimal downtime.
ETL Layer
- Azure Synapse Analytics: Pipelines re-engineered to replace legacy SSIS.
- Azure Data Factory: Orchestration of transformations and data refresh workflows.
Analytics Layer
- Azure Analysis Services: Semantic layer built on curated data.
- Azure Functions: Automated cube refresh to ensure up-to-date models.
- Power BI: Dashboards delivering insights across the retail business.
Security & Monitoring
- Azure AD & Key Vault: Identity management and secure secret storage.
- Azure Monitor & Log Analytics: Centralized observability and alerts integrated with Teams.
- Azure DevOps: CI/CD pipelines for infrastructure and data workflows.
Implementation Process
Phase 1: Assessment (2 weeks)
- Application discovery, dependency mapping, and performance baseline.
- Proof of Concept validating Synapse pipelines and automated cube refresh.
Phase 2: Preparation (2 weeks)
- Provisioning SQL Database, Synapse, ADF, and Functions.
- Configuring role-based access control and monitoring.
Phase 3: Migration (6 weeks)
- Migrated ~2 TB data and 150+ objects into Azure SQL Database using ADMS.
- Re-engineered legacy ETL into Synapse pipelines.
- Automated cube refresh with Azure Functions.
Phase 4: Cutover & Optimization (2 weeks)
- Redirected reporting workloads to Azure SQL Database.
- Validated Power BI dashboards in production.
- Optimized pipelines for performance and cost.
DevOps & Deployment Process
To support a small, agile team of four developers, the project used Azure DevOps pipelines with lightweight but effective practices.
Branching & Code Review
- Feature branches created for every change.
- Pull requests (PRs) required peer review before merging.
- Build validation enforced before merge (tests, lint checks).
- No direct commits to the
mainbranch.
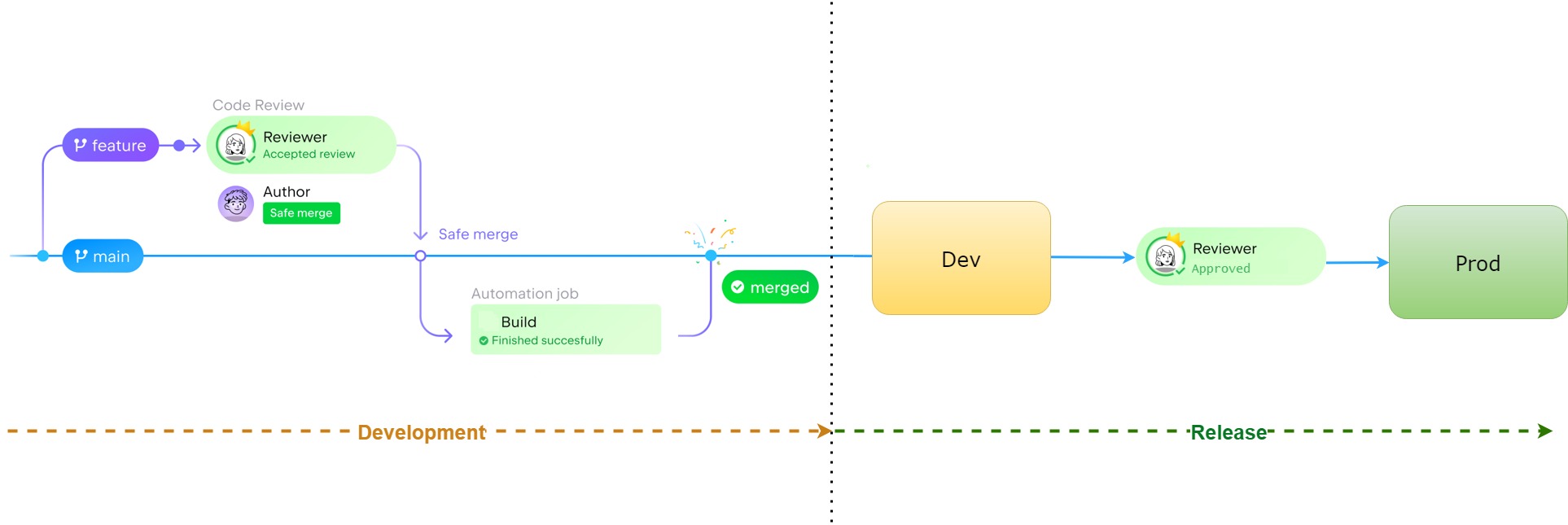
CI/CD Pipelines
- Build stage: Compiled Synapse artifacts, SQL scripts, and Function App code.
- Dev deployment: Automatic deployment to the Dev environment on merge.
- Prod deployment: Required peer approval before promotion to production.
Results and Outcomes
| Metric | Before Migration | After Migration | Improvement |
|---|---|---|---|
| System Uptime | 95% (fragile) | 99.9% | +4.9% |
| Data Refresh Cycle | 4 hours | 2 hours auto | 2x faster |
| Cube Refresh Effort | Frequent manual intervention | Automated | 100% saved |
| ETL Maintenance | High overhead | Streamlined | -70% effort |
Future Roadmap
As part of continuous modernization, the existing Azure Analysis Services layer will be decommissioned and replaced by the Power BI semantic model.
This change will:
- Reduce costs by eliminating the Analysis Services instance.
- Simplify architecture by removing an additional layer between Power BI and the data source.
- Improve performance with tighter integration between Power BI and Azure SQL/Synapse models.
Lessons Learned
- Phased migration reduced risk and allowed for incremental validation.
- Re-engineering ETL upfront simplified long-term operations.
- Automating cube refresh improved trust and timeliness of insights.
Key Recommendations
Best Practices
- Use Azure SQL Database for reliable modernization of legacy SQL workloads.
- Replace legacy SSIS with Synapse pipelines to reduce technical debt.
- Automate downstream processes with Azure Functions for efficiency.
- Integrate Azure Monitor and DevOps early to ensure governance and observability.
ETL Implementation Practices
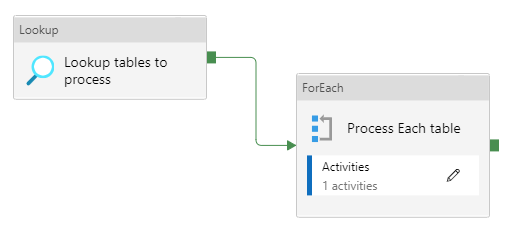
- Metadata-driven pipelines: Use external CSV/JSON metadata files to store schema definitions, column mappings, and control flags.
- Generic datasets & pipelines: Instead of creating a new pipeline for every dataset, design reusable pipeline templates that dynamically adapt based on metadata.
- Reusability & consistency: This approach ensures consistent handling of ingestion, validation, and transformations while minimizing repetitive development effort.
Example Metadata Control File (CSV)
ActivityName,TargetTable,StoredProcedure,ColumnMappings,SourcePath,FilePrefix,IsDailyLoad
ImportCustomerData,STG_Customer,[sp_Load_Customer],{"CustomerId":"Id","Name":"FullName"};/data/customers,Customer,true
ImportOrders,STG_Orders,[sp_Load_Orders],{"OrderId":"Id","Amount":"Total"};/data/orders,Order,true
The diagram below shows how a metadata-driven Synapse pipeline uses a Lookup activity to fetch metadata and a ForEach loop to dynamically process multiple datasets with reusable activities.
Conclusion
This project transformed a fragile on-prem analytics platform into a highly available, automated Azure solution. By migrating SQL Server to Azure SQL Database, modernizing ETL with Synapse pipelines, and automating cube refresh, the client achieved greater uptime, faster reporting, and lower operational overhead — creating a foundation for future analytics innovation.