
A Microsoft Fabric-based framework that accelerates enterprise data platform adoption with standardized processes and reusable patterns. This scalable solution streamlines onboarding by 4x while enabling consistent governance and implementation across teams, providing a blueprint for successful Microsoft Fabric deployments.
Industry
Technologies
Languages, frameworks, and platforms used in this project.
Azure Services
Concrete Azure resources and services provisioned.
Tags
Key Challenges
- •Unstructured ZIP archives and mixed file types (DOCX, PDF, TXT) required consistent parsing.
- •Multiple projects needed a single, reusable orchestration pattern.
- •Environment-aware runs (dev/uat/prod) and secrets/paths had to be centralized.
- •End-to-end traceability: what ran, what loaded, what failed, and where.
- •Governed releases and predictable promotion through UAT to Prod.
Key Outcomes
Summary
We developed a reusable Microsoft Fabric framework for document ingestion and analytics that scales efficiently across projects and environments. The solution implements a parent-child pipeline architecture with dynamic parameters and environment variables, applying Medallion principles to process unstructured content through Bronze (raw), Silver (processed), and Gold (analytics-ready) layers. With integrated operational telemetry, Git-based deployments, and Power BI semantic refresh capabilities, the framework provides reliable project delivery while maintaining consistent standards and governance across the organization.
Project Highlights
- Team-wide framework for Fabric projects (repo structure, naming, dev practices, logging, release strategy)
- Parent orchestrator + modular child pipelines with dynamic params and library variables
- Medallion processing of unstructured ZIPs and structured datasets
- Teams notifications and Power BI semantic refresh
- Git-based deployments with protected branches (UAT → Prod)
- Metrics & error logs tables for end-to-end observability
The Challenge
Business Limitations
- Diverse data sources and file formats required a consistent, reusable ingestion approach.
- Stakeholders needed reliable refreshes and timely updates to curated datasets/reports.
- Onboarding new projects had to be quick, discoverable, and well-documented.
Technical Hurdles
- Orchestrating unzipping, parsing, and normalization for unstructured content at scale.
- Running the same pipelines across dev/uat/prod with minimal changes.
- Enforcing naming conventions, repo structure, and release governance.
- Capturing ingestion metrics and errors for auditability and RCA.
Solution Architecture
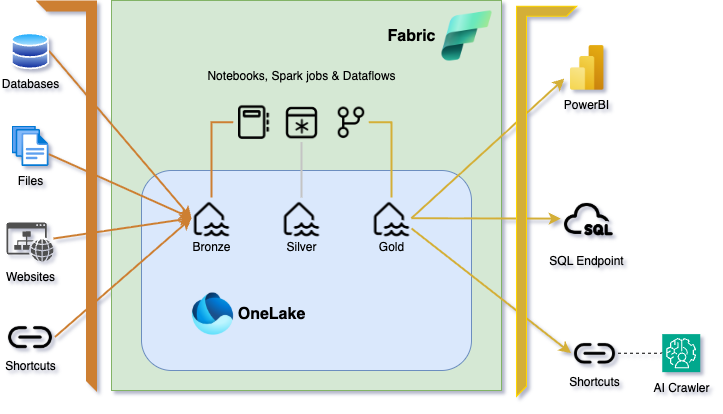
Core Components
Medallion Data Flow
- Bronze: Raw ZIPs/datasets persisted with minimal transformation.
- Silver: Unzip, metadata extraction, parsing (DOCX/PDF/TXT), cleaning/dedup.
- Gold: Curated datasets, KPIs, and semantic artifacts for reporting.
Analytics & Refresh
- Power BI semantic model refresh after Silver/Gold completion to keep reports up to date.
- Semantic layer configuration ensures consistent business metrics across reports.
- Incremental refresh patterns to optimize data loading and report performance.
AI Integration
The AI Crawler integration is particularly valuable as it:
- Indexes processed document chunks with vector embeddings
- Provides natural language search across all standards documentation
- Creates semantic connections between related standards
- Enables knowledge discovery through shortcuts to related content
- Supports Q&A interactions using the standards knowledge base
Implementation Process
Phase 1: Foundations
- Establish naming standards (tables, notebooks, schemas, pipelines), repo layout, and project README template.
- Define common utility functions and notebook templates for team reuse.
- Create version-controlled variable libraries for Dev/UAT/Prod environments.
Naming Conventions
Our standardized naming conventions ensure clarity, discoverability, and proper governance:
Comprehensive Naming Convention Guide ▼
This section outlines the standard naming conventions used in our Microsoft Fabric workspace. These conventions promote consistency, readability, and clarity across teams and projects.
General patterns
| Type | Pattern Summary |
|---|---|
| Folders | Use Pascal Case |
| Fabric objects | Use lower case with underscores(_) and meaningful prefixes |
| Constants/Parameters | Use UPPER CASE with underscores(_) and meaningful prefixes |
Detailed naming conventions
| Category | Type | Description | Prefix | Examples |
|---|---|---|---|---|
| Data structures | Table | Physical data tables | t_ | t_sales_orders |
| View | Logical representations of data | v_ | v_customer_summary | |
| Schema | Logical grouping of objects per project & layer | schema_, domain_ | schema_finance, domain_marketing | |
| Code artifacts | Notebook | Used for ETL, layer logic, or utility logic | nb_ | nb_br_finance, nb_sl_marketing, nb_utils_sql, nb_dq_sales |
| SQL script | SQL transformation or analysis logic | sql_ | sql_dq_customers | |
| Stored procedure | Scripted data transformation logic | sp_ | sp_load_sales_data | |
| User-defined function | Reusable logic as a function | udf_ | udf_calculate_discount | |
| Execution | Data pipeline | Orchestrates execution flow, movement, and dependencies | dp_ | dp_br_customers, dp_init_integration |
| Dataflow | Performs in-pipeline data transformations visually | df_ | df_customer_data_cleaning | |
| ML Model | Machine learning models per project/function | ml_ | ml_customer_churn_prediction | |
| Storage | Lakehouse | Structured/unstructured storage by team & layer | lh_ | lh_finance_bronze, lh_finance_silver |
| Warehouse | SQL-based structured data store | wh_ | wh_sales_bronze, wh_sales_silver | |
| Eventhouse | Event or streaming data store | eh_ | eh_events_bronze, eh_events_silver | |
| Support components | Environment | Environment specific libraries | env_ | env_common, env_dev |
| Variable library | Central variable definitions | vl_ | vl_project_config, vl_common | |
| Reporting | Power BI report | Business intelligence visualizations | pbi_ | pbi_sales_dashboard |
| DevOps | Feature branch | Used for development. Merges into uat. | features/<feature_id>_<project>_<functionality> | features/1234_sales_report_export |
| Hotfix branch | Used for quick fixes. Merges into uat. | hotfix/<bug_id>_<project>_<fix> | hotfix/5678_customer_data_connection |
Repository & Folder Structure
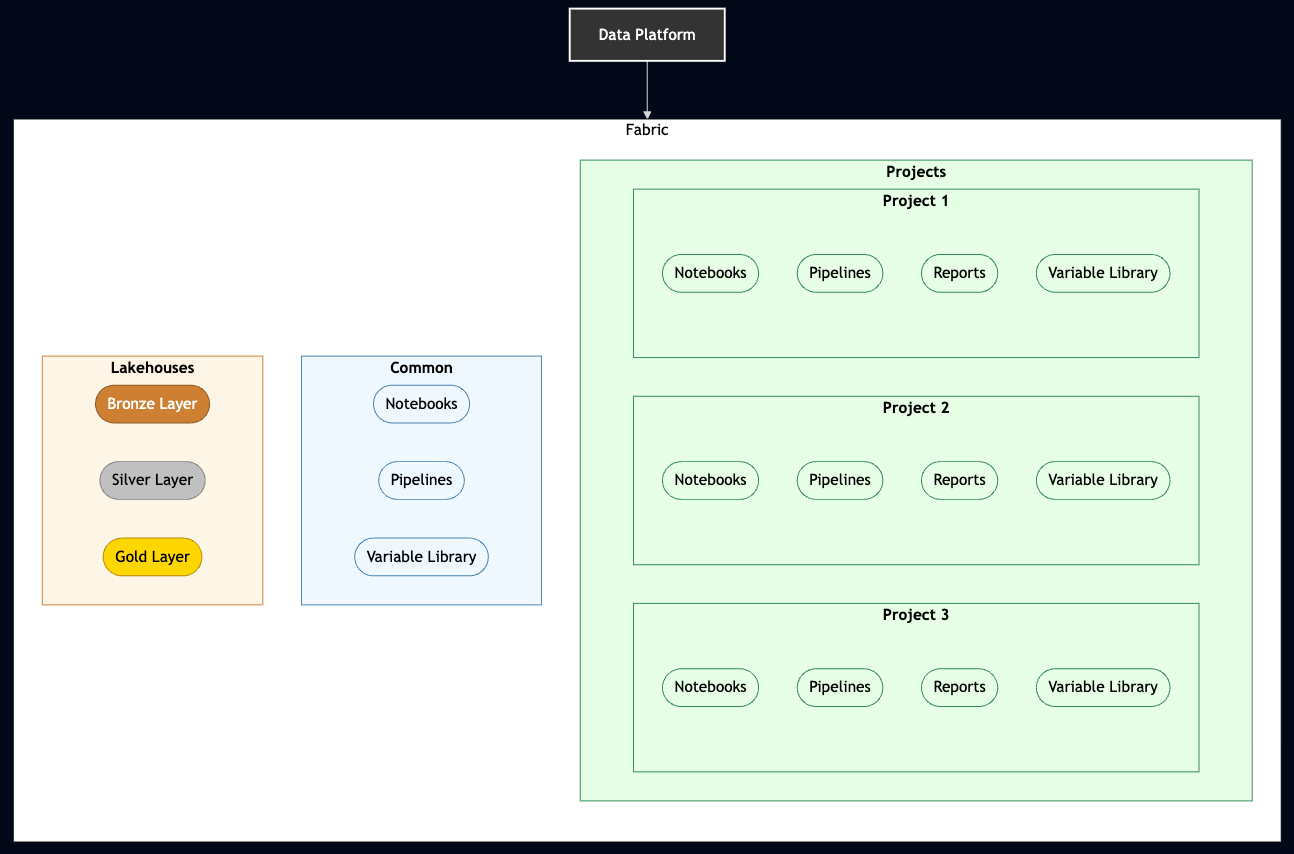
Phase 2: Orchestration & Notebooks
- Build parent orchestrator and child pipelines by layer.
- Implement modular notebooks with clear sections (params, lakehouse link, variables, imports, utils).
- Design parameterized notebook templates with environment-aware configuration.
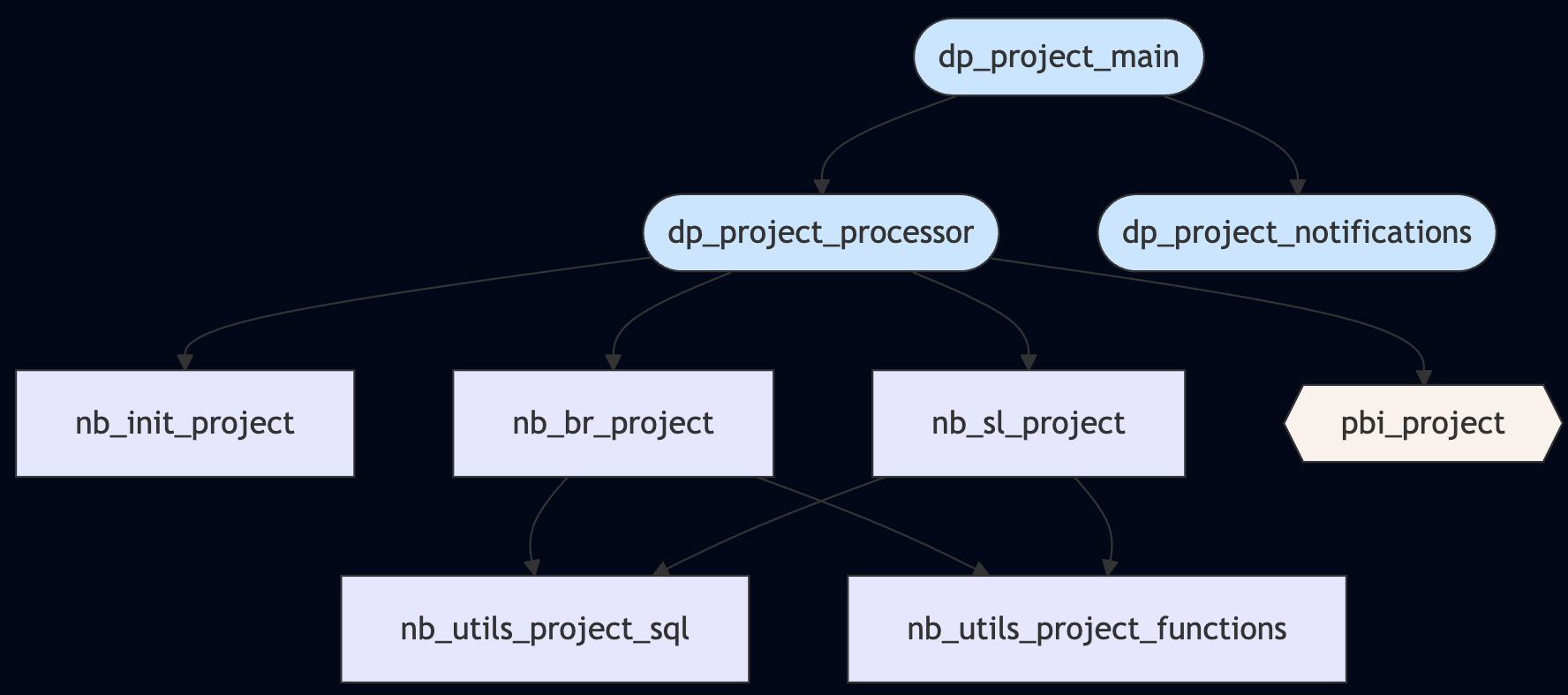
The diagram illustrates our hierarchical pipeline architecture with distinct layers and components:
| Layer | Component | Description |
|---|---|---|
| Top-level orchestration | dp_project_main | Central entry point that coordinates the entire data processing workflow |
| Processing layer | dp_project_processor | Manages all data transformation tasks |
dp_project_notifications | Handles alerting and monitoring | |
| Execution notebooks | nb_init_project | Sets up required tables, configurations, and environment validation |
nb_br_project | Processes data at the Bronze layer (raw ingestion) | |
nb_sl_project | Transforms data at the Silver layer (structured data) | |
pbi_project | Refreshes analytical models and Power BI datasets | |
| Utility layer | nb_utils_project_sql | Contains common SQL operations and queries |
nb_utils_project_functions | Houses reusable Python functions for processing |
This architecture enables clean separation of concerns while maintaining centralized orchestration. Pipeline runs can be monitored holistically through the main pipeline while allowing targeted troubleshooting of specific data processing stages.
Phase 3: Medallion & Logging
- Land raw data/ZIPs in Bronze, unzip & parse to Silver, curate to Gold.
- Emit ingestion metrics and error logs to warehouse tables for run telemetry.
- Implement semantic model refresh triggers via Functions.
Medallion Architecture
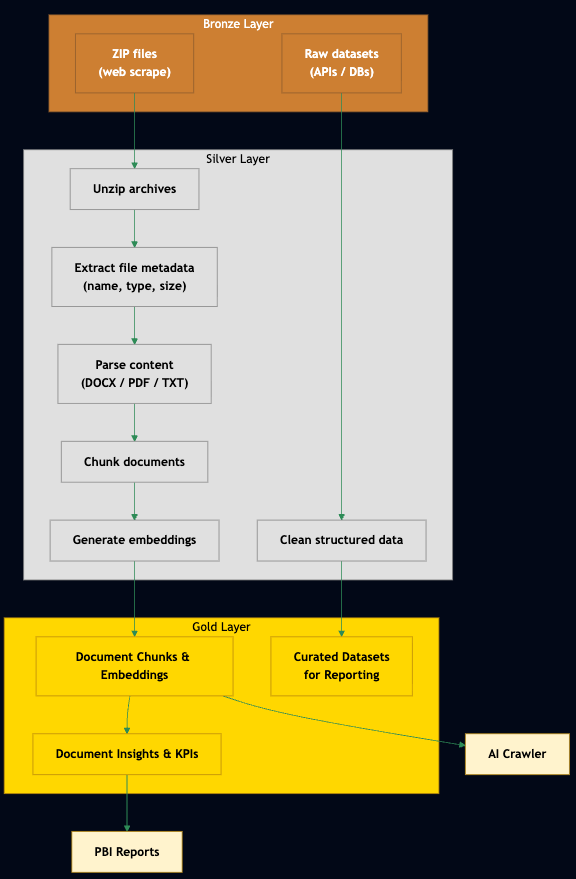
Our implementation uses a structured approach to data organization across the three medallion layers:
Detailed Lakehouse Structure ▼
Bronze Lakehouse
The Bronze layer stores raw, unmodified data as it's ingested from source systems.
| Table/Storage | Description |
|---|---|
project.raw_documents | Raw document metadata before processing. |
project.source_metadata | Source system metadata about content origin. |
/ext/data/<project_id>/<source_id>/ | File storage location for ZIP archives and raw data. |
Silver Lakehouse
The Silver layer contains parsed, cleaned, and standardized data ready for analysis.
| Table/Storage | Description |
|---|---|
project.processed_documents | Document text and metadata after extraction and parsing. |
project.document_chunks | Document content split into processable chunks. |
project.document_entities | Named entities extracted from document content. |
/ext/data/<project_id>/processed/ | Extracted and parsed documents from ZIPs. |
Gold Lakehouse
The Gold layer provides business-ready, curated datasets optimized for reporting.
| Table/Storage | Description |
|---|---|
project.document_analytics | Curated document metrics and KPIs for reporting. |
project.project_metrics | Project-level aggregated metrics and trends. |
Phase 4: Releases & Monitoring
- Adopt Git-based deployments: feature → UAT → Prod.
- Wire Teams notifications on success/failure with contextual run info.
- Trigger Power BI refresh post-pipeline.
- Deploy operational dashboards for monitoring run status and metrics.
Logging & Observability
We maintain two central warehouse tables for comprehensive operational monitoring:
| Table Name | Purpose | Key Fields | Benefits |
|---|---|---|---|
metrics.ingestion_metrics | Track successful ingestion events | source_system, source_item, source_modified_date, target_item, load_count, load_datetime | Historical trends, volume monitoring |
metrics.error_logs | Capture pipeline failures | source_system, resource_name, operation, error_message, error_datetime | Failure patterns, RCA |
These centralized metrics enable run analytics, SLA tracking, and rapid root-cause analysis across all pipelines.
Metrics Collection & Visualization
Our approach to observability combines standard Fabric metrics with the powerful Fabric Capacity Metrics App to gain deep insights into performance and resource utilization:
- Pipeline-level metrics: Duration, success rate, failure points (via
metrics.ingestion_metrics). - Asset-level metrics: Document counts, parsing success rates, file size distributions.
- Capacity utilization monitoring: Tracking compute usage by artifact type, operation, and time period.
- Throttling and bottleneck identification: Detecting and resolving performance constraints.
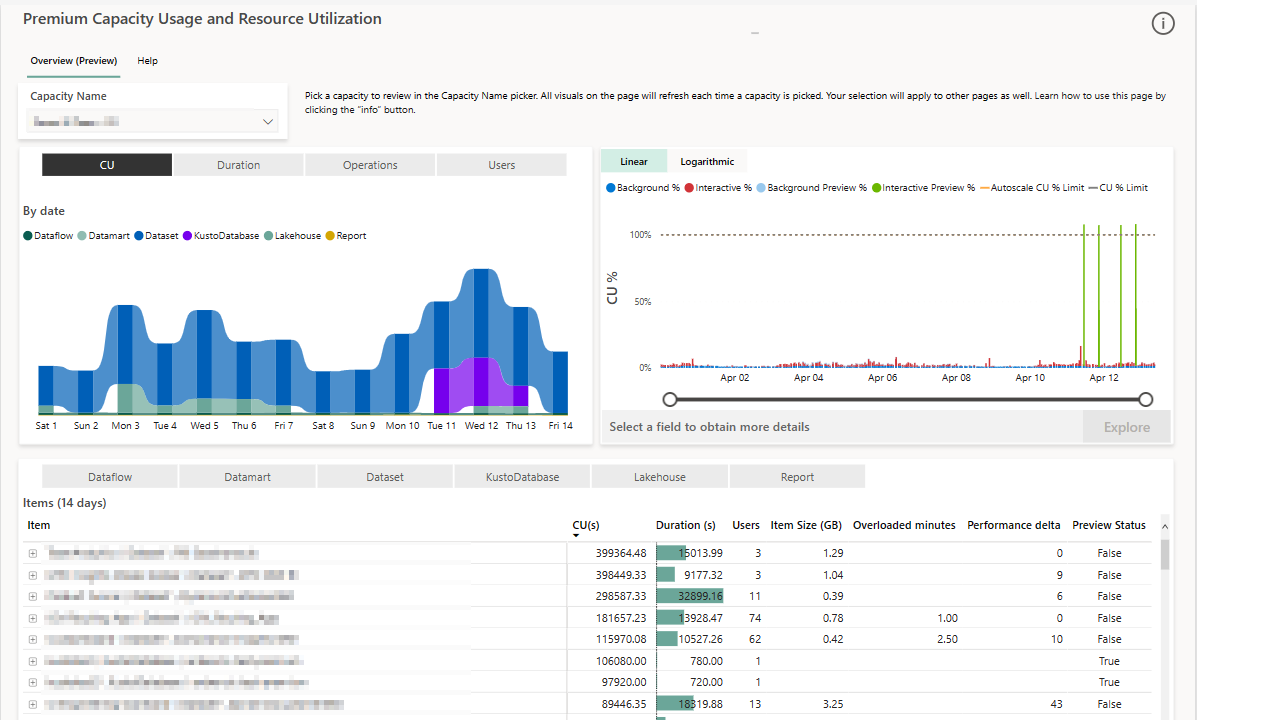
The Fabric Capacity Metrics App offers invaluable insights into our capacity utilization, allowing us to:
- Identify which artifact types and specific items are consuming the most Capacity Units (CUs)
- Monitor capacity utilization trends over time with the "CU over time" chart
- Analyze interactive vs. background process distribution
- Pinpoint specific operations driving usage through the Timepoint Details page
- Track OneLake storage consumption across workspaces
This level of visibility enables proactive capacity management, accurate resource allocation, and ensures optimal performance across our Fabric environment. For major processing jobs, we conduct pre and post-run analysis to fine-tune our resource utilization and prevent throttling during peak periods.
DevOps Process
To maintain consistency and quality across our multi-environment setup, we implemented a rigorous yet agile DevOps approach based on Microsoft Fabric's Git-based deployments (Option 1).
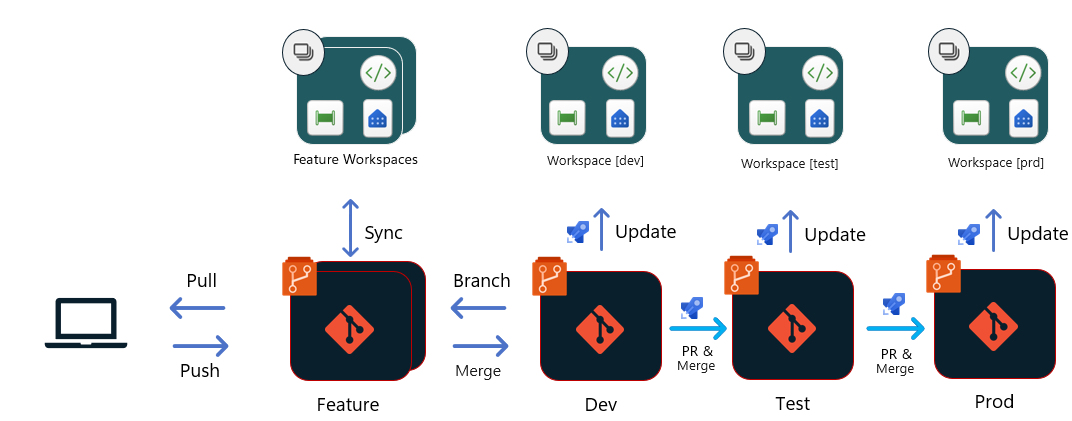
Microsoft Fabric Git-based Deployment Strategy
Our implementation follows Microsoft's recommended Git-based deployment approach, where:
- All deployments originate directly from the Git repository
- Each stage in our release pipeline has a dedicated primary branch (
dev,uat,main) - Each branch feeds the appropriate workspace in Fabric
- Changes flow through environments using Pull Requests with appropriate approvals
Why We Use Git-based Deployments (Option 1)
Our implementation follows Microsoft Fabric's Option 1 (Git-based deployments) for several key advantages:
- Single Source of Truth: Git serves as the definitive source of all deployments, ensuring complete version control and history
- Gitflow Compatibility: Our team follows a Gitflow branching strategy with multiple primary branches (
dev,uat,main), which aligns perfectly with this approach - Simplified Deployments: Direct uploads from repo to workspace streamline the deployment process
- Clear Branch-to-Environment Mapping: Each environment corresponds to a specific Git branch, making it easy to track what code is deployed where
- Automated Workspace Sync: Changes to protected branches automatically trigger workspace updates through Fabric Git APIs
For more details, see the official Microsoft Fabric CI/CD documentation: Manage deployment with CI/CD in Microsoft Fabric
Branch Protection
- Feature branches: All development begins in feature branches (e.g.,
feature/add-new-standard). - PR reviews: Required code reviews from 2+ team members with automated quality checks.
- Controlled promotion: Feature → UAT → Production with automated validation at each step.
- Protected branches: Direct commits to
uatandmainbranches are prohibited.
Git Branching Strategy

This branching strategy ensures that all code changes follow a consistent path from development through testing and finally to production. Feature branches provide isolation for development work, while protected branches maintain the stability of our UAT and Production environments. The automated workspace sync ensures that our Fabric workspaces always reflect the current state of their corresponding branches.